2017年6月29日
自動運転車に搭載される認識技術
カメラ、センサー、AIの三つの組み合わせと「エッジ」への負荷削減の重要性
おはようございます。
弊社ホームページでは、IT技術の最先端であるAI技術応用で最も重要な、最も技術を堅実に飛躍させるものとして、完全自動運転車の実用化の経緯を執拗に追いかけています。
中でもグーグルから独立してアルファベット傘下(グーグルが自らを収めるために作った親会社)に入ったウェイモは、完全自動運転車をすでに開発済みで、あとはフィアット・クライスラーにハード面を開発させて、さらに詳細なデータを取るだけなのではないかと考えています。
しかし、最近明らかになった報道でも、ウェイモはライダーという光学センサーを主要な自立運転制御のデバイスとして使っているという向きがあり、画像認識を使うのはイーロン・マスク氏のテスラのほうであるようです。テスラはGPUのNVIDIAを自社の「エッジ」として使うようで、ウェイモと並んで自動運転車開発の最先端に行く可能性があります。何より、テスラのほうは自動車メーカーなのです。
そして弊社では、日本のメーカーの現状を憂えています。しかしここにきて、パナソニックとテスラ、トヨタとNVIDIA、KDDIのIoT事業、そして孫正義氏のCPUとGPU覇権掌握といった、日本企業の動きが少しずつ、そしてかなりの先見性で活発化しています。
そこへきて本日は日本の誇る世界企業ソニーのイメージセンサー開発です。イメージセンサーというのはカメラセンサー、あるいはセンサーカメラといって、ビルや店舗にある防犯用のカメラや顧客行動の分析に使われるカメラもその一つです。
ただのカメラと違い、店舗に設置することで顧客の出入りや店舗内経路、店舗内のどこで「たまる」かなどを撮影してデータ化し、顧客分析に利用するところが特徴です。
当然、そこで集積されたデータはビッグデータとなり、データセンターに集められます。すなわちAI技術と直結したものです。さらに画像認識ディープラーニングなどと組み合わせ、自動運転車に搭載して、クルマの制御を行うことに使われ始まています。記事の後半にはやはりそのことが詳しく出ています。
これまで弊社編集部は、自動運転車はAIによる画像認識技術が主力で、それがライダーにとってかわるという見通しを持っていました。しかし、テスラは画像認証技術、ウェイモは自社でライダーを開発という事実があり、実際はどうやって自動運転車制御を行うかが混とんとしたイメージのままでした。
しかし、この記事の公判で、そのイメージは明確になります。どうやらイメージセンサー(ここにAIの画像認識が組み合わされる)、ミリ波レーダー、ライダー(LIDAR)といった三つを組み合わせることで、技術の一長一短を補い合うという方式をとるようです。
当然、クラウドや端末に作業負荷(ワークロード)がかかりすぎ、電力消費のかかりすぎやCPU、GPUでは手に負えなくなるといった問題が起こります。そこでそれまで別々であったタスクをひとまとめにするといった工夫が記事の末に書かれていますが、これが今、GPUなどの専門化チップ(specialized chips)を用途に応じて組み合わせていく潮流となって、インテルを脅かしている現実につながっています。
IT業界の巨人インテルの憂鬱
http://noteware.com/intelcar.html
謎の半導体メーカー?NVIDIAの台頭
http://noteware.com/nvidia.html
日本を代表する企業ソニーが自動運転車制御で大きな役割を果たすための具体的な開発研究を行っているというニュースは、現在世界的には全く期待されていない日本の特にIT系業界には一筋の光明のように見えます。
人の知性超えるカメラ 車載や監視、FAがけん引
2017/5/24
日本経済新聞 電子版
http://www.nikkei.com/article/DGXMZO15539880Q7A420C1000000/
イメージセンサーや画像処理技術、画像認識技術といったカメラ技術は、これまで人間の眼(視覚)を超えることを目標に進化してきた。今後は、撮影シーンや周囲の状況までを瞬時に把握できる、知性を備えたカメラ技術が開発の主戦場になる。けん引するのは、市場成長が著しい自動車やドローン、監視カメラ、産業用ロボットといった非民生分野だ。
イメージセンサーの世界シェアで首位を独走するソニーグループが、2017年第1四半期に新たな事業部を立ち上げた。それが、監視カメラやドローン、産業用ロボットといった非民生分野におけるセンシング用途に向けたイメージセンサーを手掛ける、ソニーセミコンダクタソリューションズの「センシングソリューション事業部」である。

図1 車載向けイメージセンサー第2世代品の特徴は、LEDフリッカーを抑制しつつ、HDRでダイナミックレンジ110dBを達成できること。加えて、感度も高く、0.1luxという暗い環境下でも撮影が可能とする。自動車の機能安全規格「ISO26262」の「ASIL-C」に対応する(左)。自動車の前方カメラだけでなく、電子ミラー向けカメラへの採用を狙う(右)。同ミラーに利用した場合、後方にある車両のヘッドランプを個別に識別できる水準だという
これまでソニーは、スマートフォン(スマホ)やデジタルカメラといった民生機器向けイメージセンサーに注力し、高いシェアを誇ってきた。加えて2015年には、車載事業部を立ち上げて、車載カメラのイメージセンサーにも力を入れている。

表 LEDフリッカーの抑制と広いダイナミックレンジを実現した、ソニーグループの車載向けイメージセンサー第2世代品の仕様
例えば、2017年4月には、同年5月のサンプル出荷、2018年3月の量産を予定する第2世代製品を発表した(表、図1)。「LEDフリッカー」と呼ばれるちらつき現象の抑制と、広いダイナミックレンジを両立させた。今後のソニーの車載イメージセンサーの「基盤になる製品」(ソニーセミコンダクタソリューションズ 車載事業部 車載事業企画部 統括部長の北山尚一氏)と位置付ける。
ここにきて新たに発足させたセンシングソリューション事業部は民生、車載に続く「もう1つ(第3)の柱」(同事業部 事業部長の吉原賢氏)を育てるために発足させた、ソニー“肝いり”の組織である。この事業部で開発するのは、距離や偏光、特徴量などを取得できる、これまでのイメージセンサーとは一線を画すものばかりだ(図2)。
(編集部注記: 特徴量というのはフューチャー・クァンティティといって、AIがディープラーニングで認識するもの。画像認識などで人の顔の特徴を捉え、セルフィ認証技術に使われるもの。つまり、ソニーのこの技術は単なるセンサーではなく、AI技術と密接につながっていることが読み取れる。)
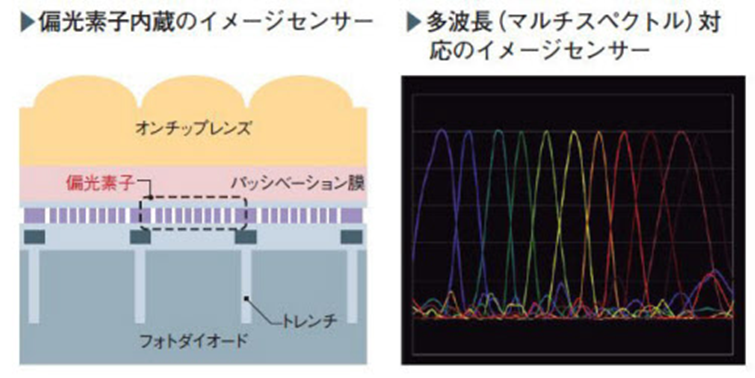

図2 イメージセンサーの金額ベースの世界シェアで首位のソニーグループは、同センサーの新たな用途開拓に向けて新たな事業部を2017年に立ち上げた。それとともに、従来よりも多様な情報を取得できるイメージセンサーを開発している。例えば、さまざまな偏光状態や波長の光を捉えられるイメージセンサー、距離画像センサー、高速なセンシングが可能な高速ビジョンチップなどである(写真:左から2番目と3番目はソニー)
見通すカメラが求められる
非民生分野のイメージセンサー開発にソニーが注力する背景には、スマホやデジタルカメラの市場成長の鈍化がある。一方で、車載カメラや監視カメラ、産業機器に利用されるマシンビジョン用途の非民生機器の市場は、民生分野のカメラに比べて高い成長を期待できる。例えば車載カメラ市場の場合、IHS Markit Technologyの調べによれば、2016年の5200万台弱から2020年に約2倍に相当する1億台を超えるまでに成長するとみている(図3)。
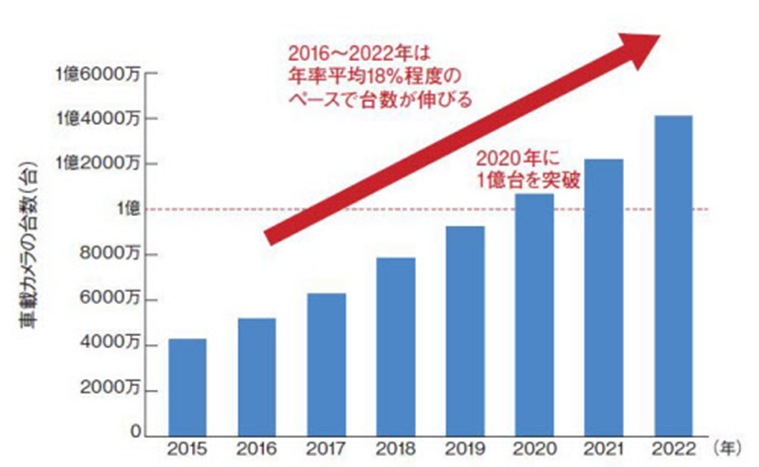
図3 IHS Markit Technologyの調べによれば、2016年に5200万台弱だった車載カメラは2020年に1億台を超えるという。2016年から2022年は、年率平均18%程度のペースで数量が伸びるとみている
成長分野として期待を集める非民生分野において、イメージセンサーや画像処理技術、画像認識技術といったカメラ技術に求められるのは、人が見たままの画像を撮影したり、見た目にきれいな画像を表現したりする視覚的な機能ではない。撮影したシーンの状況やその意味まで見通すことができる、いわば「知性」を備えたカメラ技術である。
知性を備えたカメラを実現するために、例えばイメージセンサーでは、2次元のカラー画像に加えて、距離や波長、偏光、高速フレームといったさまざま情報を取得するための技術開発が活発化している(図4)。認識の手掛かりになる情報を増やすことで、画像認識を高度化できるからだ。
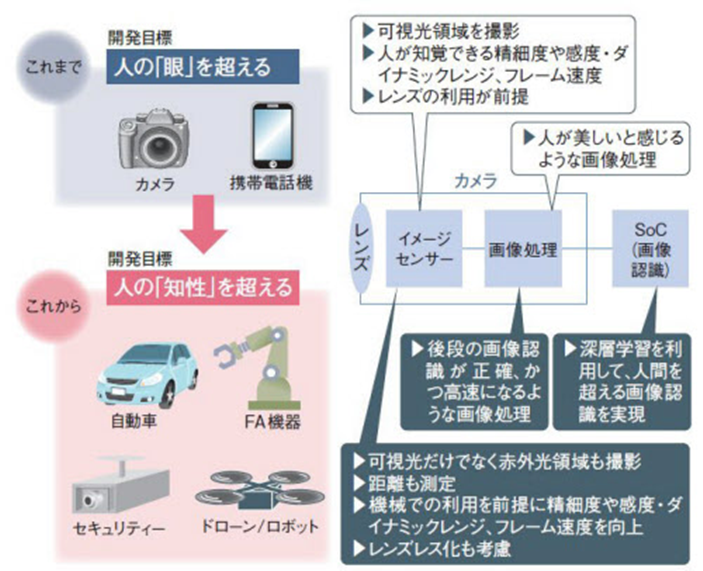
図4 イメージセンサーや画像処理技術、画像認識技術といったカメラ技術は、これまで人間の知覚を超えることを目標に開発が進められてきた。技術開発のけん引役となる主要なアプリケーションは、スマホやデジタルカメラだった。これからは、自動車やドローン、監視カメラ、FA機器といった産業機器がけん引役となる。そのため、人の知性を超えることが開発目標になる
画像処理では、後段で実行する画像認識が正確かつ高速になるような技術、画像認識では人間を超える状況判断を可能にする人工知能(AI)技術が重要になる。特に最近では、ディープラーニング(深層学習)を適用した画像認識技術の研究開発が盛んだ。
以降では、自動車の先端事例を紹介しよう。
信号・道路を含む運転シーン全体を認識
自動車分野では、自動運転に向けたセンシング技術の開発が盛んである。ただし、センサーごとに得手・不得手が存在するために、1種類のセンサーだけでなく、複数種類のセンサーを組み合わせる、いわゆる「センサーフュージョン」により完全自動運転を目指す方向が主流になっている。車載センサーとしてカメラが得意とするのは、車両や歩行者などの対象物の識別である。そこで、その識別をより人間の認識に近づける研究が進んでいる。
例えばデンソーは、深層学習を適用したニューラルネットワーク(DNN:Deep Neural Network )による画像認識に力を入れている。DNNの適用により、人や自動車のみならず、信号や道路などを含む運転シーン全体を認識できる(図5)。画像の画素ごとに、どのクラスのオブジェクトに属しているのかをラベリングする「セマンティックセグメンテーション」が可能になる。
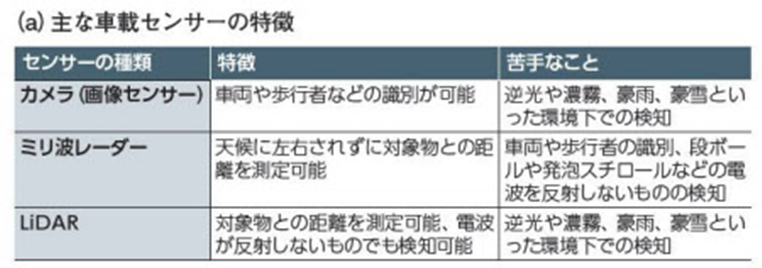

図5 デンソーは、センサーごとに得手・不得手があるので、安全性の向上や自動運転にはセンサーフュージョンが必要とみる(a)。カメラの場合、車両や歩行者などを識別しやすい特徴がある。加えて、画像認識技術の改善も図っている。その方策として開発に力を入れているのが、ディープラーニングを適用したニューラルネットワーク(DNN)である。DNNにより、運転シーン全体を認識できるようになり、自動運転時に求められる「走行するためのフリースペースの認識」や「歩行者や自動車の動き予測」などを実現しやすくなる(b)
現行の市販車に搭載されている車載カメラシステムでは、個々の自動車や人、白線などを認識している。こうした個別の認識に比べて、運転シーン全体を認識することで、その結果から「事故を予測して未然に防ぐなど、人に近い振る舞いが可能になり、安全性が高まる」(デンソー)とみている。
骨格検出と顔向き推定をリアルタイムに
自動運転で求められるのは、周辺を捉えるカメラ技術だけではない。車内カメラでも、高度な認識が必要になる。例えば「レベル3」相当の自動運転では、自動車側で自律運転ができない状況になった場合に、人手による運転に切り替える必要がある。このとき、運転手がうたた寝をしていたり、本を読んでいたりすると、スムーズな切り替えが難しい。そこで、運転手の状況をリアルタイムに把握する必要がある。その実現に向けた画像認識技術の研究開発も盛んである。
運転手の状況を高い精度で把握するには、深層学習を適用した「畳み込みニューラルネットワーク(DCNN:Deep Convolutional Neural Network)」が向く。だが、処理負荷が大きくCPU(中央演算処理装置)でのリアルタイム処理が難しい、タスクごとに個別のDCNNを用意しなければならない、といった課題がある。
そこで中部大学工学部の「Machine Perception and Robotics Group (MPRG)」は、1つのDCNNにIR(赤外線)画像と距離画像を入力することで、運転手の骨格検出と顔向き推定の2つのタスクを実行できる手法を開発した(図6)。2つのタスク向けにそれぞれDCNNを用意し、計2つのDCNNを別途実行する場合に比べて、2つのタスクを1つのDCNNで実行する方が演算負荷を軽減できる。
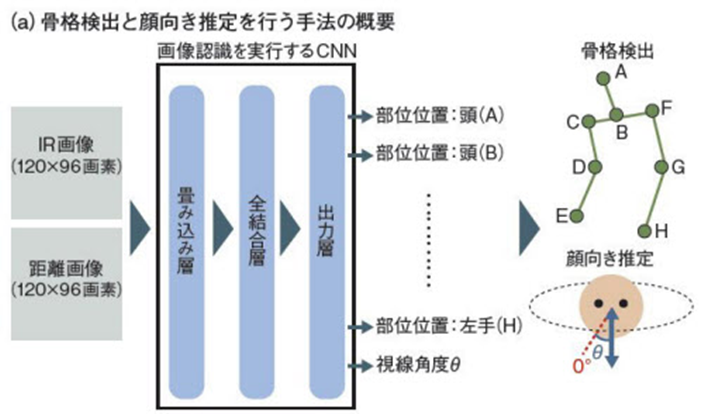

図6 1つのCNNで骨格検出と顔向き推定を同時に実行。中部大学工学部の「Machine Perception and Robotics Group (MPRG)」は、ディープラーニングを適用した畳み込みニューラルネットワーク1つで運転手の骨格検出と顔向き推定を実行できる手法を開発した。同手法をGPU、あるいはCPUで実行すると、いずれの半導体でも、骨格検出と顔向き推定にそれぞれニューラルネットワークを用意する場合に比べて処理時間を約半分にできる(図:MPRGの資料を基に日経エレクトロニクスが作成)
実際、今回の手法をGPU(画像処理半導体)、あるいはCPUで実行したところ、2つのタスク向けにそれぞれDCNNを用意する場合に比べて、骨格検出はほぼ同等の認識精度、顔向き推定はやや劣る精度で、2つのタスクの合計処理時間を約半分にできた。
CPUの場合でも34.1ミリ秒と、30フレーム/秒弱の撮影であればほぼリアルタイムに骨格検出と顔向き推定を実行できる水準である。